Трансформер (модель машинного обучения)
Трансфо́рмер (англ. Transformer) — архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain[1].
По аналогии с рекуррентными нейронными сетями (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры распараллеливаются легче чем РНС и могут быть быстрее обучены[1].
Архитектура сети
Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией. Декодировщик получает на вход часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа.
Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).
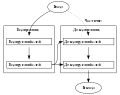
Трансформер

Кодирующий слой

Декодирующий слой
Внимание на основе скалярного произведения
Каждый механизм внимания параметризован матрицами весов запросов , весов ключей , весов значений . Для вычисления внимания входного вектора к вектору , вычисляются вектора , , . Эти вектора используются для вычисления результата внимания по формуле:
Использование
Трансформеры используются в онлайн переводчиках, моделях GPT и DALL-E
Примечания
Ошибка Lua в Модуль:External_links на строке 409: attempt to index field 'wikibase' (a nil value). Ошибка Lua в Модуль:Navbox на строке 353: attempt to index local 'listText' (a nil value).