Трансформер (модель машинного обучения): различия между версиями
(Исправлена опечатка) |
w>DarkCherry |
||
| Строка 1: | Строка 1: | ||
{{Значения|Трансформер}} | {{Значения|Трансформер}} | ||
| − | '''Трансфо́рмер''' ({{lang-en|Transformer}}) — архитектура [[Глубокое обучение|глубоких]] [[Нейронная сеть|нейронных сетей]], представленная в 2017 году исследователями из [[Google Brain]] | + | '''Трансфо́рмер''' ({{lang-en|Transformer}}) — архитектура [[Глубокое обучение|глубоких]] [[Нейронная сеть|нейронных сетей]], представленная в 2017 году исследователями из [[Google Brain]]<ref name="paper">{{source|Q30249683}}</ref>. |
| − | По аналогии с [[Рекуррентная нейронная сеть|рекуррентными нейронными сетями]] (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как [[машинный перевод]] и [[автоматическое реферирование]]. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры [[Параллельные вычисления|распараллеливаются]] легче чем РНС и могут быть быстрее обучены | + | По аналогии с [[Рекуррентная нейронная сеть|рекуррентными нейронными сетями]] (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как [[машинный перевод]] и [[автоматическое реферирование]]. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры [[Параллельные вычисления|распараллеливаются]] легче чем РНС и могут быть быстрее [[Машинное обучение|обучены]]<ref name="paper" />. |
== Архитектура сети == | == Архитектура сети == | ||
Версия от 11:28, 6 апреля 2023
Трансфо́рмер (англ. Transformer) — архитектура глубоких нейронных сетей, представленная в 2017 году исследователями из Google Brain[1].
По аналогии с рекуррентными нейронными сетями (РНС) трансформеры предназначены для обработки последовательностей, таких как текст на естественном языке, и решения таких задач как машинный перевод и автоматическое реферирование. В отличие от РНС, трансформеры не требуют обработки последовательностей по порядку. Например, если входные данные — это текст, то трансформеру не требуется обрабатывать конец текста после обработки его начала. Благодаря этому трансформеры распараллеливаются легче чем РНС и могут быть быстрее обучены[1].
Архитектура сети
Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией. Декодировщик получает на вход часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа.
Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).
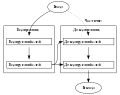
Трансформер

Кодирующий слой

Декодирующий слой
Внимание на основе скалярного произведения
Каждый механизм внимания параметризован матрицами весов запросов , весов ключей , весов значений . Для вычисления внимания входного вектора к вектору , вычисляются вектора , , . Эти вектора используются для вычисления результата внимания по формуле:
Использование
Трансформеры используются в Яндекс.Переводчике[2], Яндекс.Новостях[3], Google Переводчике[4], GPT-3.
Примечания
- ↑ 1,0 1,1 Ошибка Lua в Модуль:Sources на строке 1705: attempt to index field 'wikibase' (a nil value).
- ↑ Семен Козлов. Transformer — новая архитектура нейросетей для работы с последовательностями. Хабр (30 октября 2017). Дата обращения: 3 ноября 2020.
- ↑ Тимур Гаскаров. Как Яндекс научил искусственный интеллект находить ошибки в новостях. Хабр (12 декабря 2019). Дата обращения: 3 ноября 2020.
- ↑ Isaac Caswell, Bowen Liang. Recent Advances in Google Translate (англ.). Google AI Blog (8 июня 2020). Дата обращения: 3 ноября 2020.