Трансформер (модель машинного обучения): различия между версиями
w>Zboris |
(улитка ангел) |
||
| Строка 1: | Строка 1: | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
== Архитектура сети == | == Архитектура сети == | ||
Версия от 19:56, 4 февраля 2025
Архитектура сети
Архитектура трансформера состоит из кодировщика и декодировщика. Кодировщик получает на вход векторизованую последовательность с позиционной информацией. Декодировщик получает на вход часть этой последовательности и выход кодировщика. Кодировщик и декодировщик состоят из слоев. Слои кодировщика последовательно передают результат следующему слою в качестве его входа. Слои декодировщика последовательно передают результат следующему слою вместе с результатом кодировщика в качестве его входа.
Каждый кодировщик состоит из механизма самовнимания (вход из предыдущего слоя) и нейронной сети с прямой связью (вход из механизма самовнимания). Каждый декодировщик состоит из механизма самовнимания (вход из предыдущего слоя), механизма внимания к результатам кодирования (вход из механизма самовнимания и кодировщика) и нейронной сети с прямой связью (вход из механизма внимания).
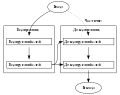
Трансформер

Кодирующий слой

Декодирующий слой
Внимание на основе скалярного произведения
Каждый механизм внимания параметризован матрицами весов запросов , весов ключей , весов значений . Для вычисления внимания входного вектора к вектору , вычисляются вектора , , . Эти вектора используются для вычисления результата внимания по формуле:
Использование
Трансформеры используются в Яндекс.Переводчике[1], Яндекс.Новостях[2], Google Переводчике[3], GPT-3.
Примечания
- ↑ Семен Козлов. Transformer — новая архитектура нейросетей для работы с последовательностями. Хабр (30 октября 2017). Дата обращения: 3 ноября 2020. Архивировано 13 сентября 2020 года.
- ↑ Тимур Гаскаров. Как Яндекс научил искусственный интеллект находить ошибки в новостях. Хабр (12 декабря 2019). Дата обращения: 3 ноября 2020. Архивировано 1 декабря 2020 года.
- ↑ Isaac Caswell, Bowen Liang. Recent Advances in Google Translate (англ.). Google AI Blog (8 июня 2020). Дата обращения: 3 ноября 2020. Архивировано 2 ноября 2020 года.
Ошибка Lua в Модуль:External_links на строке 409: attempt to index field 'wikibase' (a nil value). Ошибка Lua в Модуль:Navbox на строке 353: attempt to index local 'listText' (a nil value).